32 Discussion 05: Transformation, Probability & Sampling (From Summer 2025)
32.1 Logarithmic Transformations
Ishani is a development economist interested in studying the relationship between literacy rates and gross national income in countries across the world. Originally, she plotted the data on a linear (absolute) scale, shown on the left. She noticed that the non-linear relationship between the variables with a lot of points clustered towards the larger values of literacy rate, so she consults the Tukey-Mosteller Bulge diagram and decides to do a \(\log_{10}\) transformation of the y-axis, shown on the right. The solid blue line is a “line of best fit” (we’ll formalize this later in the course).
![]()
The goal here is to think about the meaning of the \(\log\) transformation, not just memorize “when to log-transform” data. The problem setup gives you a visual cue to guide your thinking.
For part (a), consider when the other descriptions might also be appropriate.
Remember: log-transforming data reduces the impact of large values by making them smaller, which can make patterns in the data easier to see.
32.1.1 (a)
Instead of using the \(\log_{10}\) transformation of the y-axis, what other transformations could Ishani have used to attempt to linearize the relationship between literacy rate (\(x\)) and gross national income per capita (\(y\)). Select all that apply.
Answer
32.1.2 (b)
Let \(C\) and \(k\) be some constant values and \(x\) and \(y\) represent literacy rate and gross national income per capita, respectively. Based on the plots, which of the following best describes the pattern seen in the data?
Answer
\(y = kx + b\) is the basic format of the regression line. Since the graph on the right takes the log scale of the y-axis, we can write the equation as \(\log_{10}y = kx + b\) and manipulate it until we get \(y\) on it’s own: \[ \begin{align} \log_{10}(y) &= kx + b \\ 10^{\log_{10}(y)} &= 10^{kx + b} \\ y &= 10^{kx} \cdot 10^b \\ y &= 10^b \cdot 10^{kx} \end{align} \]
Hence, this equation format fits choice B, \(y = C \cdot 10^{kx}\), where \(C = 10^b\).
32.1.3 (c)
What parts of the plots could you use to make initial guesses on \(C\) and \(k\)?
Answer
- C: \(10^b\), where \(b\) is the y-intercept of the solid blue line in the transformed plot.
- k: the slope of the solid blue line in the transformed plot.
32.1.4 (d)
Ishani’s friend, Yash, points to the solid line on the transformed plot and says “since this line is going up and to the right, we can say that, in general, the higher the literacy rate, the greater the gross national income per capita”. Is this a reasonable interpretation of the plot?
Answer
Yes, the observation is equivalent to saying that the slope is positive, which means increases in \(x\) correspond to increases in \(y\). This does not mean higher literacy rates cause higher gross national incomes, just that they are positively correlated.32.1.5 (e)
Suppose that instead of plotting positive quantities, our data contained some zero and negative values. How can we reasonably apply a logarithmic transform to this data?
Answer
Logs cannot take on zero or negative values, so we must shift our data into positive quantities before applying a logarithmic transform. To achieve this, we add the magnitude (or absolute value) of the most negative number in our data and then add a small positive number (e.g., 1). As a concrete example, suppose we had the dataset: \({-3, -2, 4}\). The most negative number is -3, so we add \(|-3| = 3\) to all numbers to obtain: \({0, 1, 7}\). This fixes the issue with negative values, but this dataset still contains the value 0. Hence, we add a small positive number such as 1, to get the numbers \({1, 2, 8}\) that we can finally apply the \(log\) operation to.32.1.6 (f) (Extra)
They go on to say “since the slope of this line is less than 1, we see that, in general, mammals with greater mass tend to spend less energy per gram than their smaller counterparts”. Is this a reasonable interpretation of the plot?
Answer
Yes, a slope between 0 and 1 means that \(k\) is likely between 0 and 1. Looking at \(\frac{dy}{dx}\), we see that for these values of \(k\), as \(x\) grows, its effect on \(y\) diminishes. In this case, it means that gram-for-gram larger mammals spend less energy than their smaller counterparts.32.2 Data Collection through Sampling
It’s time for the Data 100 midterm, and the professors want to estimate the difficulty of the exam. They decided to survey students on the exam’s difficulty with a 10-point scale and then use the mean of the student’s responses as the estimate.
32.2.1 (a)
What is the population the professors are interested in trying to understand?
Answer
32.2.2 (b)
The professors consider a few different methods for collecting the survey data about the midterm. Which of the following methods is best? (Think through which considerations go into “best”)
Answer
- It would be a fairly easy method. However, the quality of the data would be suspect. By sampling only from students who attend synchronously, the professors are restricting students who prefer not to attend live sessions. These can introduce selection bias in the sample.
- This method of sampling works well for this scenario because the professors are sampling randomly from students across different backgrounds and schedules, which helps capture variation along many axes. They are also embedding the question in required homework, which reduces non-response bias, and students can respond privately, reducing social desirability bias.
- This method is not ideal because discussion attendance is not mandatory this semester, which introduces selection bias—only students who choose to attend discussions will be included. As a result, the sample may not be representative of the entire class. Additionally, asking students during the section could increase social desirability bias, as students may feel pressure to respond in a certain way in front of peers or instructors.
- The primary issue here is one of social pressure because students are being asked in groups, and this can bias the results of the survey. Additionally, discussion attendance isn’t mandatory this semester, and there’s bias from who chooses to attend.
Each sampling method has its strengths and weaknesses, but choice B is generally the best option.
Think about the pros and cons of each method. For example, even choice B leaves out students who don’t look at or complete their homework.
Take some time to discuss the advantages and disadvantages of each option — there’s often no perfect method, but weighing trade-offs helps you choose the most appropriate one.
32.3 Simple Linear Regression
Lillian and Prabhleen were watching their favorite chemistry Youtuber NileRed experimenting with turning gloves into grape soda and wanted to try it themselves. The experiment was done at various temperatures and yielded various amounts of grape soda. Since this reaction is very costly, they were only able to do it 10 times. This data set of size \(n = 10\) (Yield data) contains measurements of yield from an experiment done at five different temperature levels. The variables are \(y\) = yield in liters and \(x\) = temperature in degrees Fahrenheit. Below is a scatter plot of our data.
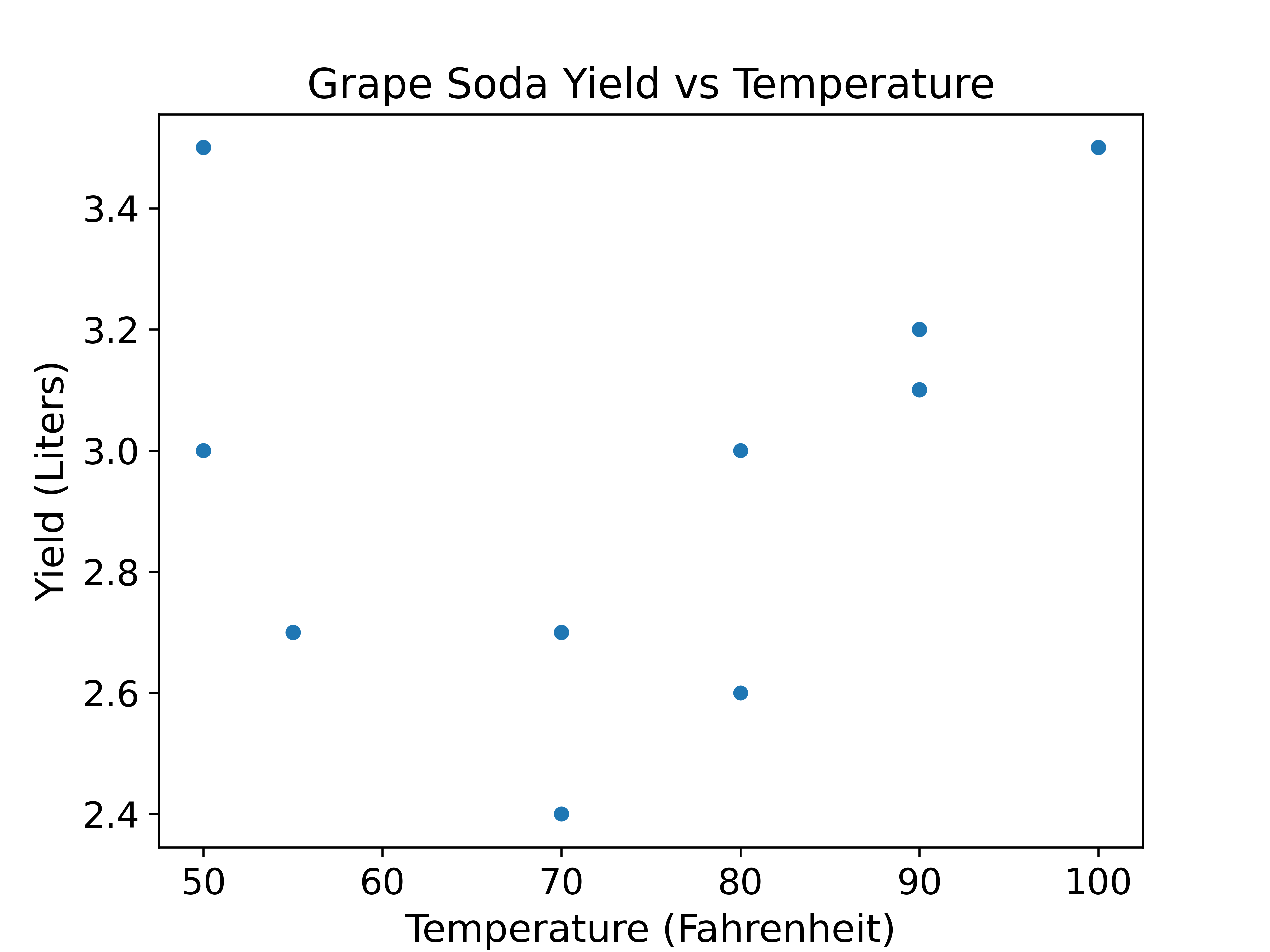
| \(\sigma_x\) | \(\sigma_y\) | \(r\) | \(\bar{x}\) | \(\bar{y}\) |
|---|---|---|---|---|
| \(15\) | \(0.3\) | \(0.50\) | \(75.00\) | \(3\) |
32.3.1 (a)
Given the above statistics, calculate the slope (\(\hat{\theta}_1\)) and y-intercept (\(\hat{\theta}_0\)) of the line of best fit using Mean Squared Error (MSE) as our loss function and plot the line on the graph above:
\[ y = \hat{\theta}_0 + \hat{\theta}_1 x \]
Answer
\(\hat{\theta}_1 = r \frac{\sigma_y}{\sigma_x}\)
\(\hat{\theta}_1 = 0.5 \frac{0.3}{15} = 0.01\)
\(\hat{\theta}_0 = \bar{y} - \hat{\theta}_1 \bar{x}\)
\(\hat{\theta}_0 = 3 - 75.00*0.01 = 3 - 0.75 = 2.25\)
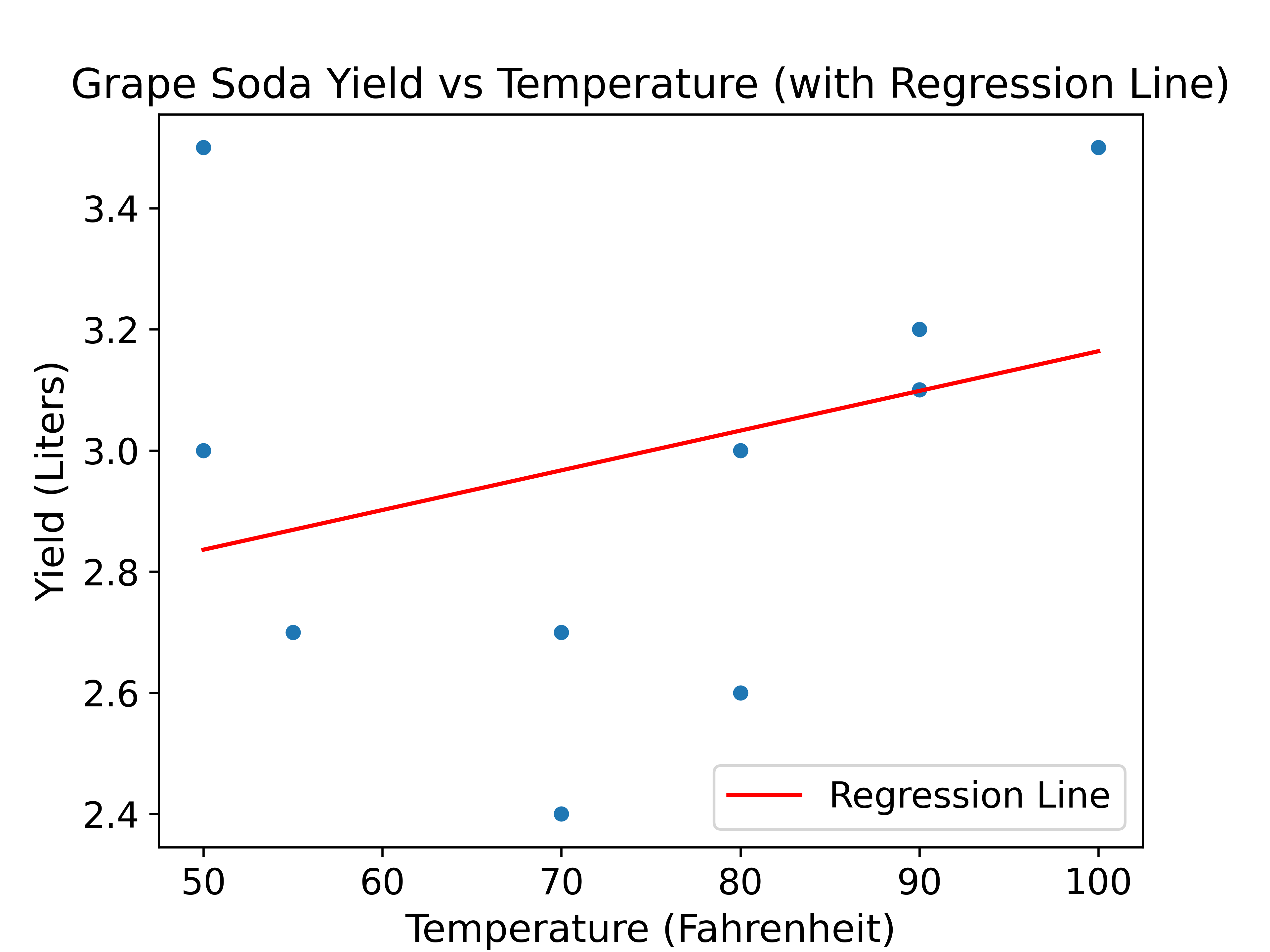
32.3.2 (b) (Extra)
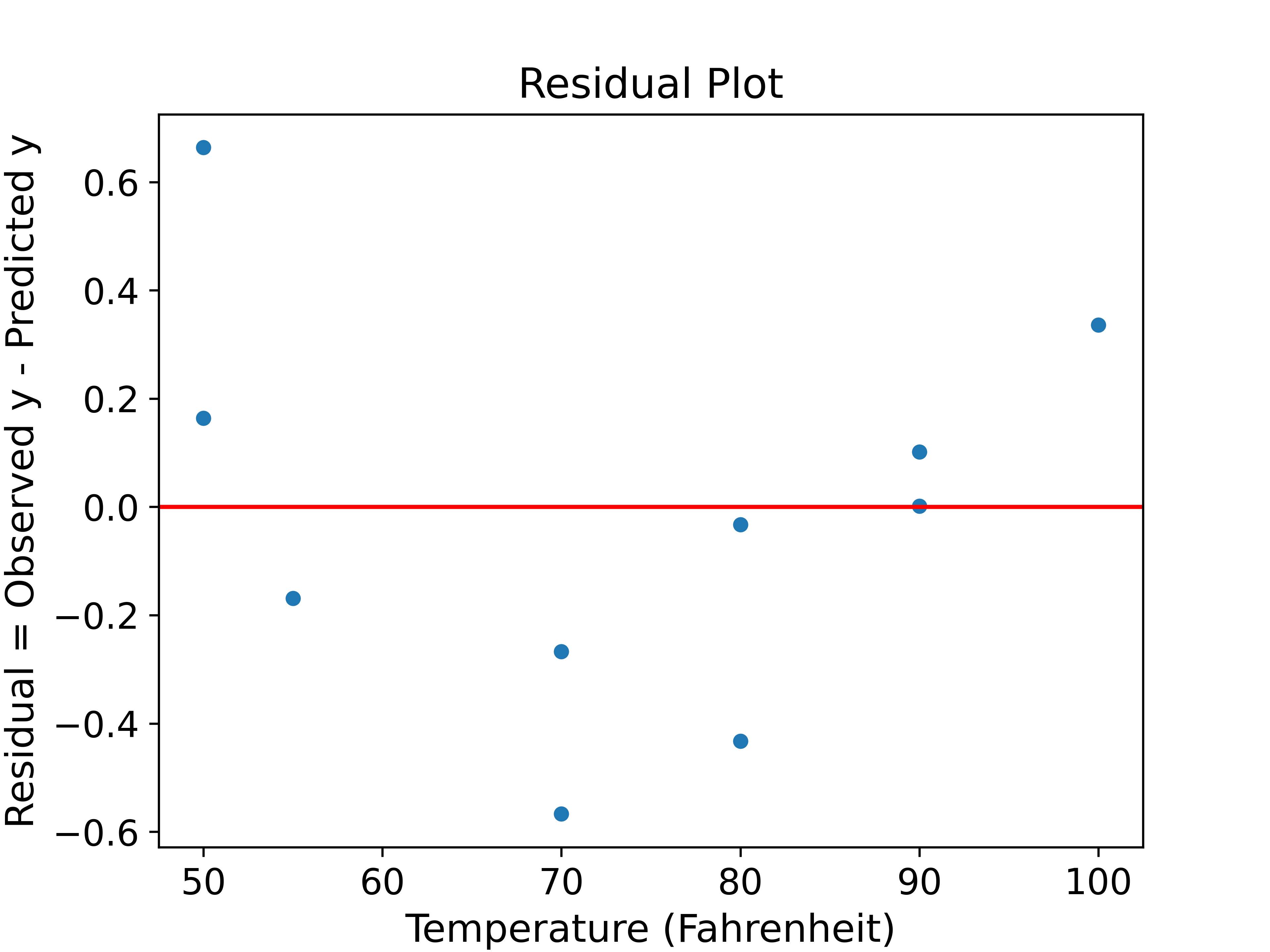
Below, you can find a plot of the residuals from the line of best fit you calculated in part (a). What does the residual plot tell us about the relationship between x and y?
Answer
The plot of the residuals is not equally variable across all values of \(x\). This means that there is heteroscedasticity in our residuals. Thus, the relationship between \(x\) and \(y\) is likely not linear. \(y\) is likely not linear in terms of \(x\).32.3.3 (c) (Extra)
Which of the following relations most closely represent the relationship we see between Temperature (\(x\)) and Yield (\(y\))?