35 Discussion 08: Cross-Validation, Regularization & Random Variables (From Summer 2025)
35.1 Cross Validation
35.1.1 (a)
After running \(5\)-fold cross-validation, we get the following mean squared errors for each fold and value of \(\lambda\) when using Ridge regularization:
| Fold Num. | \(\lambda = 0.1\) | \(\lambda = 0.2\) | \(\lambda = 0.3\) | \(\lambda = 0.4\) | Row Avg |
|---|---|---|---|---|---|
| 1 | 80.2 | 70.2 | 91.2 | 91.8 | 83.4 |
| 2 | 76.8 | 66.8 | 88.8 | 98.8 | 82.8 |
| 3 | 81.5 | 71.5 | 86.5 | 88.5 | 82.0 |
| 4 | 79.4 | 68.4 | 92.3 | 92.4 | 83.1 |
| 5 | 77.3 | 67.3 | 93.4 | 94.3 | 83.0 |
| Col Avg | 79.0 | 68.8 | 90.4 | 93.2 |
Suppose we wish to use the results of this 5-fold cross-validation to choose our hyperparameter \(\lambda\), among the following four choices in the table. Using the information in the table, which \(\lambda\) would you choose? Why?
Answer
We should use \(\lambda = 0.2\) because this value has the least average MSE across all folds.
Once we’ve chosen \(\lambda\) = 0.2, the next step is to retrain the model using the entire training set with this value of \(\lambda\).
After retraining, we estimate the model’s error using the test set to see how well it performs on new data.
35.1.2 (b)
You build a model with two hyperparameters, the coefficient for the regularization term (\(\lambda\)) and our learning rate (\(\alpha\)). You have 4 good candidate values for \(\lambda\) and 3 possible values for \(\alpha\), and you are wondering which \(\lambda, \alpha\) pair will be the best choice. If you were to perform 5-fold cross-validation, how many validation errors would you need to calculate?
Answer
There are \(4 \times 3 = 12\) pairs of \(\lambda, \alpha\), and each pair will have \(5\) validation errors, one for each fold. So, there would be 60 validation errors in total.35.1.3 (c) (Extra)
Explain how you would use leave-one-out cross validation to choose \(\lambda\) as in part a.
Answer
Each fold contains all the data except for a single point. If we have \(n\) data points, we have \(n\) folds. For each of the \(n\) folds, we train our model with a particular \(\lambda\) and evaluate the squared error of our prediction and true response value of the held-out point.35.2 Ridge and LASSO Regression
The goal of linear regression is to find the \(\theta\) value that minimizes the average squared loss. In other words, we want to find \(\hat{\theta}\) that satisfies the equation below:
\[\hat{\theta} = \arg\min_{\theta} L(\theta) = \arg\min_{\theta} \dfrac{1}{n}||\mathbb{Y} - \mathbb{X}{\theta}||_2^2\]
Here, \(\Bbb{X}\) is a \(n \times (p + 1)\) matrix, \(\theta\) is a \((p + 1) \times 1\) vector and \(\mathbb{Y}\) is a \(n \times 1\) vector. Recall that the extra \(1\) in \((p+1)\) comes from the intercept term. As we saw in lecture, the optimal \(\hat{\theta}\) is given by the closed-form expression \(\hat{\theta} = (\Bbb{X}^T\Bbb{X})^{-1}\Bbb{X}^T \mathbb{Y}\).\
To prevent overfitting, we saw that we can instead minimize the sum of the average squared loss plus a regularization term \(\lambda g(\theta)\). The optimization problem for such a regularized loss function then becomes:
\[ \hat{\theta} = \arg\min_{\theta} L(\theta) = \arg\min_{\theta} \left[ \frac{1}{n} \|\mathbb{Y} - \mathbb{X}\theta\|_2^2 + \lambda g(\theta) \right] \]
- If we use the function \(g(\theta) = \sum_{j=1}^p\theta_j^2 = ||{\theta}||_2^2\), we have “Ridge regression’’. Recall that \(g\) is the \(\ell_2\) norm of \(\theta\), so this is also referred to as ``\(\ell_2 / L_2\) regularization”.
- If we use the function \(g(\theta) = \sum_{j=1}^p |\theta_j| = ||{\theta}||_1\), we have “LASSO regression’’. Recall that \(g\) is the \(\ell_1\) norm of \(\theta\), so this is also referred to as ``\(\ell_1 / L_1\) regularization”.
In this question, we intentionally choose to regularize also on the intercept term to simplify the mathematical formulation of Ridge and LASSO regression. However, in practice, we typically do not want to regularize the intercept term (and you should always assume that the intercept is not regularized unless stated otherwise). Regularizing the intercept can actually increase the model’s mean squared error (MSE), as it prevents the model from freely shifting the prediction line up or down to better fit the data—especially when the target values are far from zero. The intercept helps capture the overall level of the data, and restricting it can hinder the model’s ability to achieve a good baseline fit.
For example, if we choose \(g(\theta) = ||{\theta}||_2^2\), our goal is to find \(\hat{\theta}\) that satisfies the equation below:
\[ \hat{\theta} = \arg\min_{\theta} L_2(\theta) = \arg\min_{\theta} \left[ \frac{1}{n} \|\mathbb{Y} - \mathbb{X} \theta\|_2^2 + \lambda \|\theta\|_2^2 \right] = \arg\min_{\theta} \left[ \frac{1}{n} \sum_{i=1}^n (y_i - \mathbb{X}_{i,\cdot}^T \theta)^2 + \lambda \sum_{j=0}^d \theta_j^2 \right] \]
Recall that \(\lambda\) is a hyperparameter that determines the impact of the regularization term. Like ordinary least squares, we can also find a closed-form solution to Ridge regression: \(\hat{\theta}=(\Bbb{X}^T\Bbb{X} + n \lambda \mathbf{I})^{-1} \Bbb{X}^T \mathbb{Y}\). For LASSO regression, there is no such closed-form expression because it is non-differentiable at 0.
35.2.1 (a)
Suppose we are dealing with the OLS case (i.e., don’t worry about regularization yet). We increase the complexity of the model until test error stops decreasing. If we continue to increase model complexity, what do we expect to happen to the training error of the model trained using OLS? What about the test error?
Answer
The training error decreases since the model fits/recognizes more relationships between features and responses found in the training dataset. However, these relationships increasingly become specific to the training set and will not necessarily generalize to the test set, so we expect the test error to increase.
In most cases, this is what we expect to happen. However, there are rare situations where the outcome might be different. Keep this in mind when interpreting results.
35.2.2 (b)
Now suppose we choose one of the above regularization methods, either L1 or L2, for some regularization parameter \(\lambda > 0\) then we solve for our optimum. In terms of variance, how does a regularized model compare to ordinary least squares regression (assuming the same features between both models)?
Answer
Regularized regression has a lower variance relative to ordinary least squares regression. This is because regularization tends to make the model “simpler” (pushing the vector of regression coefficients to be in some ball around the origin). So, upon slight changes in input variables, our predictions will vary less under regularization than under no regularization.35.2.3 (c)
Suppose we have a large number of features (10,000+), and we suspect that only a handful of features are useful. Would LASSO or Ridge regression be more helpful in interpreting useful features? Why?
Answer
LASSO would be better as it sets many values to 0, so it would be effectively selecting useful features and “ignoring” less useful ones.
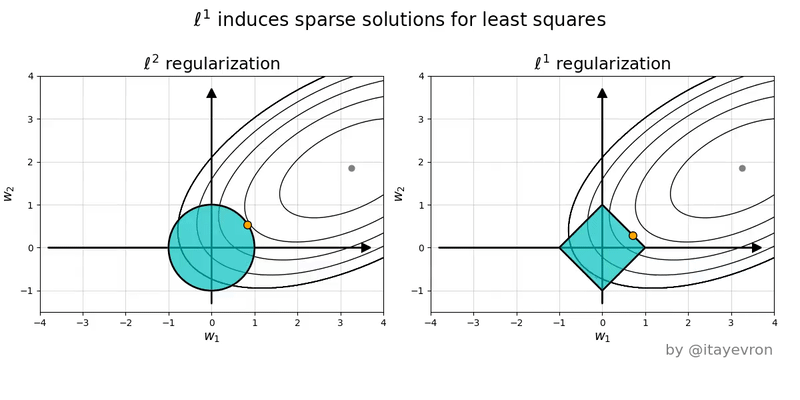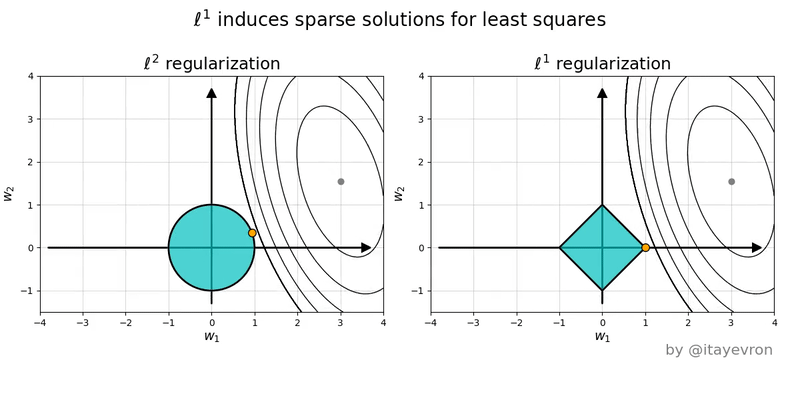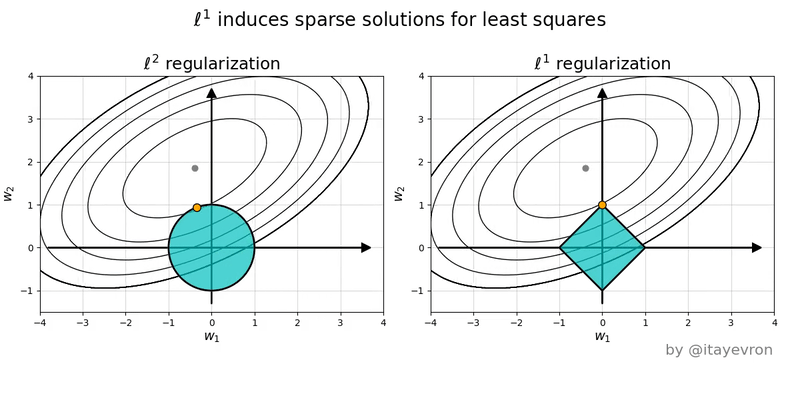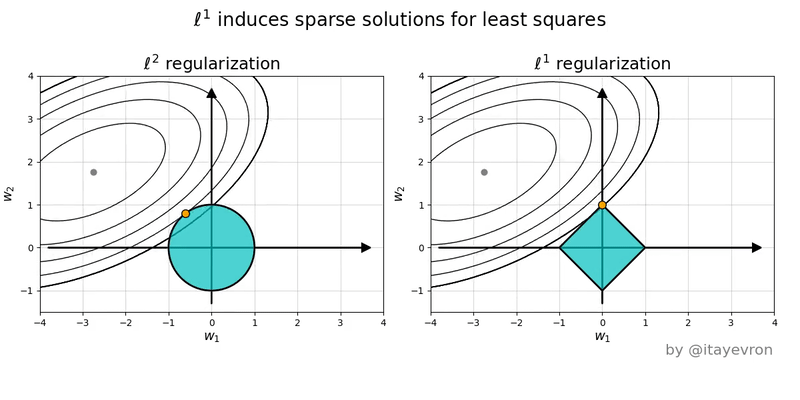
If you’re still confused, it can help to draw the constraint sets for L1 (diamond) and L2 (ball) regularization, along with some contour plots for least squares.
Notice that the minimum of the least squares plot over the diamond region (L1) tends to occur at the corners of the diamond, meaning that at least one feature is set to 0.
Helpful illustration: L1 vs L2 regularization visualization
{kind=link}
35.2.4 (d)
What are the two benefits of using Ridge regression over OLS?
Answer
If \(\mathbb{X}^T\mathbb{X}\) is not full rank (not invertible), then we end up with infinitely many solutions for least squares. On the other hand, using Ridge regression guarantees invertibility of \((\mathbb{X}^T\mathbb{X} + n \lambda \mathbb{I})\) and ensures that \(\hat\theta = (\mathbb{X}^T\mathbb{X} + n \lambda \mathbb{I})^{-1}\mathbb{X}^T\mathbb{Y}\) always has a unique solution when \(\lambda > 0\); the proof for these facts is out of scope for Data 100.
Ridge regression also allows for feature selection/reducing overfitting because it down weights features that are less important in predicting the response. However, it still stands that LASSO is normally better for feature selection since LASSO will actually set these unimportant coefficients to \(0\) as opposed to just down-weighting them.
This part is a great chance for class discussion! Think about the concepts and share your ideas with your peers.
35.2.5 (e)
In Ridge regression, what happens to \(\hat{\theta}\) if we set \(\lambda = 0\)? What happens as \(\lambda\) approaches \(\infty\)?
Answer
If we set \(\lambda=0\), \[\hat{\theta}=(\Bbb{X}^T\Bbb{X} + n \lambda \mathbf{I})^{-1} \Bbb{X}^T \mathbb{Y} =(\Bbb{X}^T\Bbb{X})^{-1} \Bbb{X}^T \mathbb{Y}\] which is the familiar OLS solution.
As \(\lambda\) approaches \(\infty\), the \((\Bbb{X}^T\Bbb{X} + n \lambda \mathbf{I})^{-1}\) term goes to zero, so \(\hat{\theta}\) goes to \(\vec{0}\) as well. The penalty term in the loss will dominate the least-squares term, so minimizing the full loss function becomes the problem of minimizing the penalty term, which is achieved at \(\hat{\theta} = \pmb{0}\)
Relate this back to the previous parts:
If \(\boldsymbol{\hat{\theta}} = \mathbf{0}\), then the model variance is 0 because for every \(x\), the model always predicts 0.
Even though you haven’t formally done the bias-variance decomposition yet, note that this model likely has a high prediction error due to its bias, despite having low variance.
35.3 Guessing at Random
A multiple choice test has 100 questions, each with five answer choices. Assume for each question that there is only one correct choice. The grading scheme is as follows:
- 4 points are awarded for each right answer.
- For each other answer (wrong, missing, etc), one point is taken off; that is, -1 point is awarded.
A student hasn’t studied at all and therefore selects each question’s answer uniformly at random, independently of all the other questions.
Define the following random variables:
- \(R\): The number of answers the student gets right.
- \(W\): The number of answers the student does not get right.
- \(S\): The student’s score on the test.
If you’ve never seen random variables before, this question might feel overwhelming.
Follow each step carefully and refer to the relevant results from class to make sure you understand what’s happening.
35.3.1 (a)
What is the distribution of \(R\)? Provide the name and parameters of the appropriate distribution. Explain your answer.
Answer
\(R\) is counting the number ofsuccesses'' (or 1s) out of $100$ total independent Bernoulli trials, where asuccess’’ is defined as answering the question correctly, and each question is a trial. The trials are independent because the student selects a random answer with the same probability distribution, no matter whether the other answers are chosen. The probability of ``success’’ on any single trial is \(1/5 = 0.2\), so, \(R\) must follow a binomial distribution with \(n = 100\) and \(p = 0.2\).
35.3.2 (b)
Find \(\mathbb{E}[R]\)
Answer
From class, the expectation of a \(\text{Binomial}(n,p)\) random variable is always \(np\). So, we obtain: \[\mathbb{E}[R] = n \cdot p = 100 \cdot 0.2 = 20\]
Remember that a binomial random variable is just a sum of Bernoulli random variables.
If you forget what its expectation is, you can write it as a sum of Bernoullis and then apply the linearity of expectations to compute it.
35.3.3 (c)
True or False: \(\text{SD}(R) = \text{SD}(W)\)? Remember that \(\text{Var}(X) = \text{SD}(X)^2\).
Answer
True. Note that \(R + W = 100\). Hence,
\[ \begin{aligned} \text{Var}(R) &= \text{Var}(100 - W) \\ &= (-1)^2 \text{Var}(W) \\ &= \text{Var}(W) \end{aligned} \]
We use the non-linearity of variance, \(\text{Var}(aX+b) = a^2 \text{Var}(X)\), to simplify the expression.35.3.4 (d)
True or False: \(\text{Var}(R + W) = \text{Var}(2R)\).
Answer
False. While \(R\) and \(W\) have the same distribution (since \(W = 100 - R\) and both are binomially related), they are not independent, nor are they the same random variable.
We know that: \[ R + W = 100 \] so \(R + W\) is a constant, and therefore: \[ \text{Var}(R + W) = \text{Var}(100) = 0. \]
However, \[ \text{Var}(2R) = 4\text{Var}(R), \] which is strictly greater than 0, since \(R\) is a random variable.
This demonstrates that even if two random variables have the same distribution, expressions involving both of them (like sums) depend on their relationship. In this case, \(R\) and \(W\) are perfectly negatively correlated—they add to a constant—which is why their sum has zero variance.35.3.5 (e)
Find \(\mathbb{E}[S]\), the student’s expected score on the test.
Answer
The student’s score on the test is a function of how many they get correct and how many they get incorrect. Using the point scheme given in the question, we can write this score as \(S = 4R - W\) since each correct answer is awarded \(4\) points, and each wrong answer is penalized by \(1\) point. Note that \(S\) is also a random variable since it is a function of random variables \(R\) and \(W\). Note that \(R + W = 100\), since there are \(100\) questions. Substituting \(W = 100 - R\) and using linearity of expectations, we see:
\[ \begin{aligned} \mathbb{E}[S] &= \mathbb{E}[4R - W] \\ &= \mathbb{E}[4R - 100 + R] \\ &= \mathbb{E}[5R - 100] \\ &= 5\mathbb{E}[R] - 100 \end{aligned} \]
Substituting \(\mathbb{E}[R] = 20\) from part (b), we see the students expected score on the exam using this guessing strategy is \(0\).35.3.6 (f)
Find \(\text{SD}(S)\).
Answer
We know from the question above that we can write \(4R - W\) as \(5R - 100\). Since the variance of a random variable plus a constant is just the variance of the original random variable:
\[ \begin{align*} \text{Var}(S) &= \text{Var}(5R - 100) \\ &= 5^{2}\text{Var}(R) \\ &= 25\text{Var}(R) \end{align*} \]
We know that the variance of a \(\text{Binomial}(n,p)\) variable is \(np(1-p)\). Plugging in the values of \(n, p\) from part (a), we see \(\text{Var}(R) = 16\), giving us \(\text{Var}(S) = 400\). Hence, \(SD(S) = \sqrt{400} = 20\).
It can be helpful to understand why we compute things like the expectation and standard deviation of a random variable:
- The expectation tells us the average score a student would get if they took the test multiple times using the same strategy.
- On any single attempt, the score may differ from this expectation.
- The standard deviation (or variance) gives us a sense of the variability—how much we expect the score to differ from the average.